
Der LLM Hardware-Kostenrechner von onprem.ai
Unser LLM Hardware-Kostenrechner ist ein SLA-basiertes webbasiertes Tool, das Unternehmen dabei unterstützt, die Hardware-Anforderungen und Kosten für den Betrieb eigener Large Language Models (LLMs) professionell zu kalkulieren.
Im Unterschied zu einfachen Sizing-Tools dimensioniert dieser Rechner Ihre Hardware auf Basis von Service Level Agreements (SLAs), dem Industriestandard für zuverlässige, planbare IT-Infrastruktur.
Was ist ein SLA?
Ein Service Level Agreement definiert messbare Leistungsgarantien für IT-Services. Im Kontext von KI-Infrastruktur bedeutet das: “Alle Nutzenden erhalten mindestens X Tokens pro Sekunde, Y% der Zeit.”
Warum sind SLAs wichtig?
- Zuverlässigkeit: Nutzende erwarten konsistente Performance, nicht sporadische Verzögerungen
- Planbarkeit: Messbare Metriken statt vager “sollte ausreichen”-Schätzungen
- Verantwortlichkeit: IT kann dem Business klare Performance-Zusagen machen
- Budgetsicherheit: Hardware wird weder über- noch unterdimensioniert
Ohne SLAs dimensionieren Sie nach Bauchgefühl. Mit SLAs haben Sie mathematische Garantien.
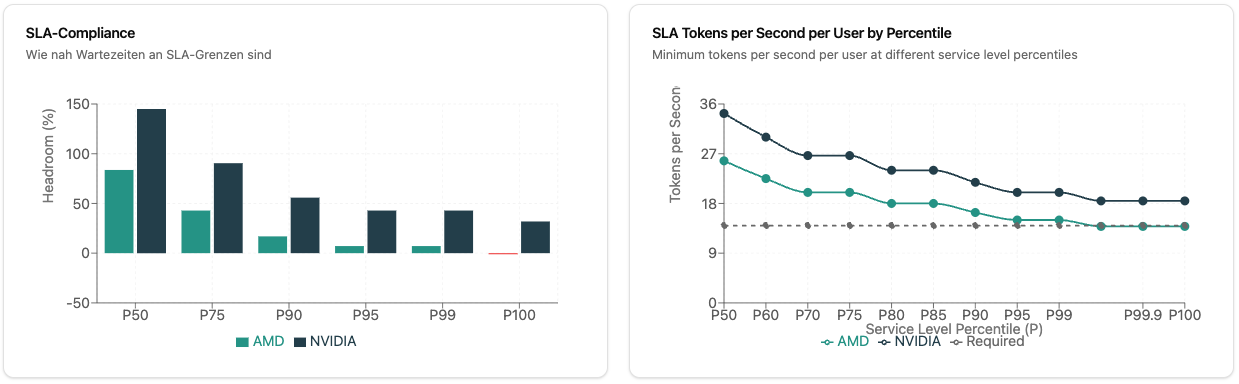
Hardware-Dimensionierung mit SLA-Garantien
Das Herzstück des Rechners: Sie definieren Service Level Agreements, der Rechner liefert die passende Hardware.
Wie funktioniert die Berechnung?
Der Rechner verwendet einen statistisch validierten, nutzer-zentrierten Ansatz: Er garantiert allen Nutzenden eine Mindest-Performance, selbst in Spitzenlastzeiten wenn alle gleichzeitig mit dem LLM interagieren. Die Konkurrenz-Berechnung basiert auf statistischen Verteilungsmodellen, die aus realen Unternehmensnutzungsmustern abgeleitet wurden. Das bedeutet: Der Rechner rät nicht einfach, wie viele Nutzende gleichzeitig aktiv sein werden, er nutzt mathematische Methoden, die widerspiegeln, wie Menschen tatsächlich in professionellen Umgebungen arbeiten. Der Algorithmus berechnet die erwartete gleichzeitige Nutzerlast auf Ihrem gewählten Service-Level und reserviert die garantierte minimale LLM-Geschwindigkeit in Tokens pro Sekunde für alle aktiven Nutzenden. Background-Tasks nutzen intelligent die Idle-Kapazität. Nur wenn sie diese übersteigen, wird zusätzliche Hardware eingeplant.
Ihre Einstellungen:
- Minimum Tokens/Sekunde pro Person: Garantierte Antwortgeschwindigkeit (z.B. 20 tok/s für flüssiges Streaming)
- Service Level Percentile: Wie oft soll diese Garantie gelten?
- P90 = 90% der Zeit (kostenoptimiert, für unkritische Anwendungen)
- P95 = 95% der Zeit (Standard für professionelle Umgebungen)
- P99 = 99% der Zeit (hochverfügbar, für geschäftskritische Systeme)
- P100 = 100% der Zeit (Worst-Case-Absicherung, maximale Redundanz)
Der Rechner dimensioniert die Hardware so, dass Ihre SLAs mathematisch garantiert eingehalten werden, auch bei Spitzenlast.
Realistische Workload-Konfiguration
Der Rechner unterscheidet zwischen verschiedenen Nutzertypen:
- Business Users (Büromitarbeiter): Typische Nutzung für E-Mail-Assistenz, Dokumentenbearbeitung, Zusammenfassungen
- Developers (Entwickler): Intensive Nutzung mit Code-Editoren, großen Kontexten, Code-Reviews
- Background Tasks: Automatisierte Prozesse wie Dokumentenverarbeitung, APIs, Batch-Jobs, konfigurierbar nach Häufigkeit und Tokenmenge
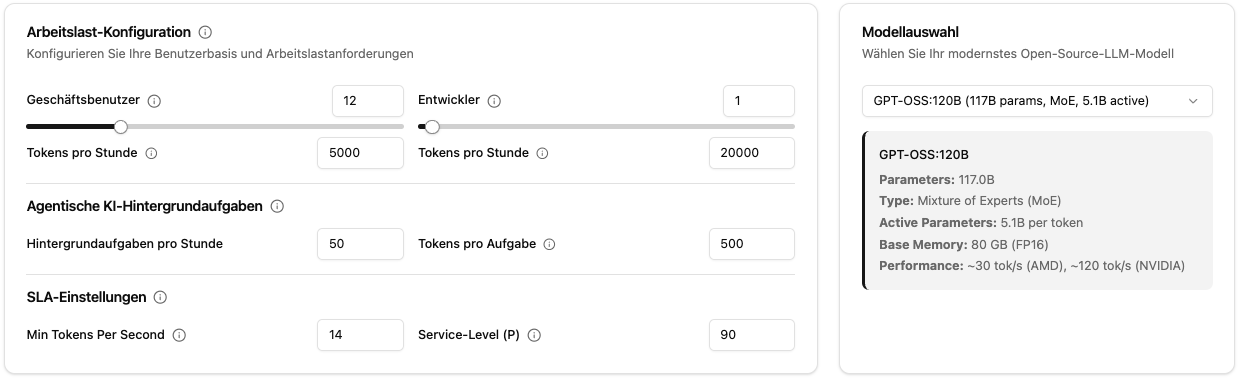
Voreingestellte Branchen-Szenarien-Beispiele
Der Rechner bietet vorkonfigurierte Presets für typische Unternehmensszenarien für einen schnellen Start ohne mühsames Schätzen:
- Software-Startup: 3 Büromitarbeiter, 6 Entwickler, Code-Analyse und Testing
- Kleine Anwaltskanzlei: 5 Büromitarbeiter, Dokumentenverarbeitung, Rechtsrecherche
- Buchhaltungsfirma: 12 Büromitarbeiter, 1 Entwickler, umfangreiche Datenverarbeitung
- Finanzberatung (mittel): 25 Büromitarbeiter, 2 Entwickler, Finanzberichte, Marktanalysen
- Arztpraxis: 8 Büromitarbeiter, Patientenakten, medizinische Berichte
- IT-Dienstleister (mittel): 18 Büromitarbeiter, 45 Entwickler, Log-Analyse, System-Monitoring
- Medizintechnik: 7 Büromitarbeiter, 10 Entwickler, hohe Zuverlässigkeitsanforderungen (P99 SLA)
- CNC-Werkstatt: 6 Büromitarbeiter, 4 Entwickler, CAD-Verarbeitung, Fertigungsdokumentation
Jedes Preset enthält realistische Standardwerte für Token-Verbrauch, Background-Tasks und empfohlene SLA-Levels basierend auf Branchenanforderungen. Sie können jedes Preset als Ausgangspunkt nehmen und individuell anpassen.
Hardware-Vergleich: AMD vs. NVIDIA
Der Rechner vergleicht beide Plattformen unter identischen SLA-Bedingungen:
- AMD Ryzen AI Max+ 395: Ideal für MoE-Modelle, kosteneffizient, niedrigerer Stromverbrauch
- NVIDIA RTX Pro 6000: Höchste Performance, besser für große Dense-Modelle, höherer Durchsatz
Sie sehen direkt: Wie viele Einheiten benötigen Sie für Ihre SLAs? Was kostet das? Wie unterscheiden sich Strom und Kühlung?
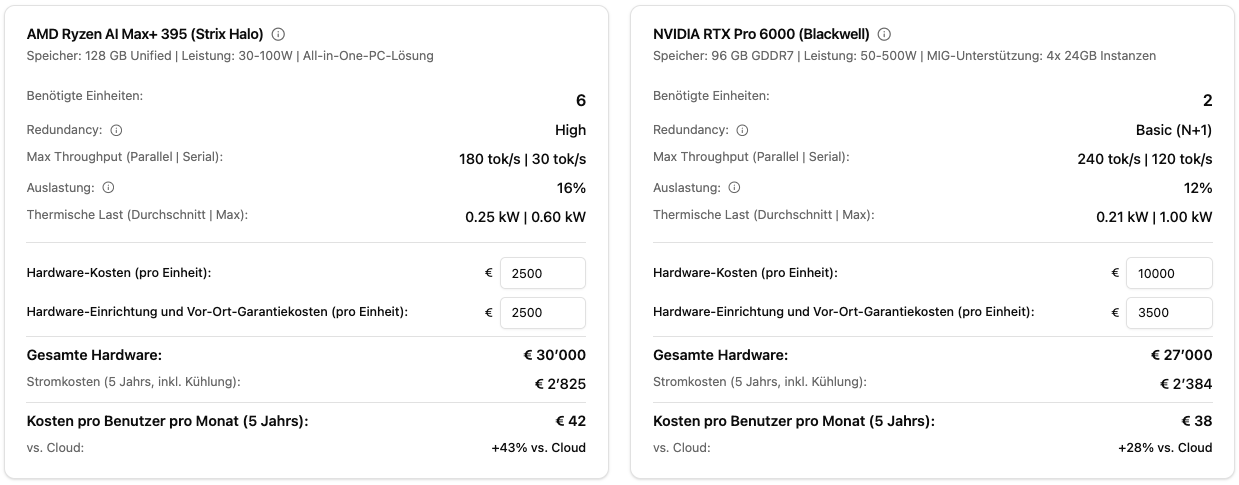 Der Rechner zeigt in Echtzeit die benötigte Hardware für Ihre SLA-Anforderungen mit AMD und NVIDIA im direkten Vergleich
Der Rechner zeigt in Echtzeit die benötigte Hardware für Ihre SLA-Anforderungen mit AMD und NVIDIA im direkten Vergleich
Modellauswahl
Der Rechner konzentriert sich auf große Open-Source-Modelle (30B+ Parameter), die den Stand der Technik für professionelle Unternehmensanwendungen repräsentieren. Diese Modelle bieten überlegene Reasoning-Fähigkeiten, besseres Befolgen von Anweisungen und höhere Qualität der Ausgaben, die die Infrastrukturinvestition rechtfertigen. Kleinere Modelle können für spezifische Aufgaben geeignet sein, aber für umfassende KI-Bereitstellungen, die vielfältige Geschäftsanforderungen erfüllen, bieten große Modelle das beste Gleichgewicht zwischen Fähigkeit und Kosteneffizienz.
Unterstützte Modelle:
- GPT-OSS:120B (MoE, 5.1B aktive Parameter), exzellent für AMD-Hardware
- DeepSeek-V2 67B (MoE, ~7B aktive Parameter)
- Mistral Large 2 67B (Dense)
- Llama 3.1 32B (Dense)
- Qwen 2.5 32B (Dense)
Für jedes Modell werden automatisch berechnet: Speicherbedarf, Memory-Bandwidth, erwartete Token-Geschwindigkeit pro Sekunde auf AMD/NVIDIA.
Visualisierungen & Analytics
Der Rechner bietet mehrere Diagramme:
- Cost Breakdown: Hardware vs. Setup vs. Strom über die Jahre
- Token Source Breakdown: Woher kommt Ihre Last? (Business Users, Developers, Background)
- SLA Compliance: Wie viel Headroom haben Sie bei P50, P75, P90, P95, P99, P100?
- Tokens/Second per User: Garantierte Performance bei verschiedenen gleichzeitigen Nutzungslevels
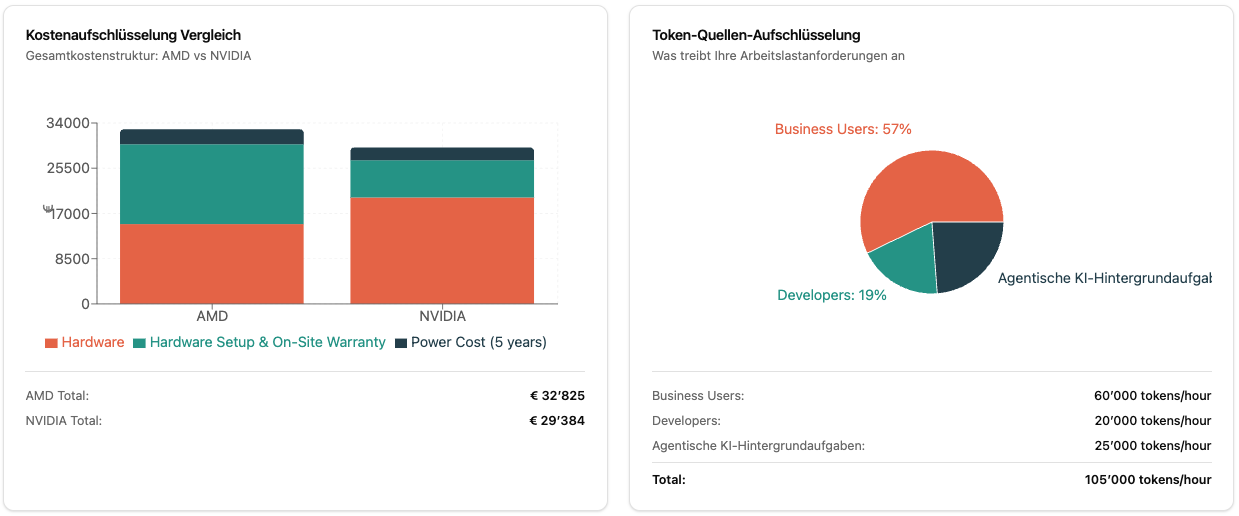 Detaillierte Kostenaufschlüsselung, Token-Verteilung und SLA-Compliance-Analysen helfen bei der fundierten Entscheidungsfindung
Detaillierte Kostenaufschlüsselung, Token-Verteilung und SLA-Compliance-Analysen helfen bei der fundierten Entscheidungsfindung
Technische Grundlagen
Der Rechner basiert auf realen Benchmark-Daten:
- AMD Ryzen AI Max+ 395: 128 GB Unified Memory, ~210-215 GB/s Bandwidth, besonders effizient für MoE-Modelle
- NVIDIA RTX Pro 6000 Blackwell: 96 GB VRAM, ~1.6-1.8 TB/s Bandwidth, höchste Token/Sekunde-Raten
Die Berechnungen berücksichtigen:
- Memory Bandwidth als Hauptflaschenhals bei LLM-Inferenz
- Aktive Parameter bei MoE-Modellen (nicht alle 120B müssen durch die Pipeline)
- Concurrency-Muster (nicht alle Nutzenden sind gleichzeitig aktiv)
- Thermal Load (idle vs. peak power consumption)
Wie Sie den Rechner nutzen
- Besuchen Sie calculator.onprem.ai
- Wählen Sie ein Branchen-Preset oder konfigurieren Sie Ihre Nutzerzahlen manuell
- Wählen Sie Ihr bevorzugtes LLM-Modell
- Definieren Sie Ihre SLA-Anforderungen (Token/Sekunde, Percentile)
- Passen Sie Kosten an (Hardwarepreise, Stromtarif, Währung)
- Vergleichen Sie AMD vs. NVIDIA und On-Premises vs. Cloud
Die URL aktualisiert sich automatisch mit allen Parametern. Sie können Szenarien bookmarken und mit Kolleg:innen teilen.
Souveräne KI und Datenkontrolle
On-Premises LLM-Deployment ermöglicht Souveräne KI (Sovereign AI) mit vollständiger Kontrolle über Ihre KI-Infrastruktur und Daten. Anders als bei Cloud-Lösungen verlassen Ihre Daten niemals Ihre Infrastruktur und gewährleisten:
- Volle Datensouveränität: Erfüllung von DSGVO, HIPAA und branchenspezifischen Compliance-Anforderungen
- Unabhängigkeit von Anbietern: Kein Lock-in zu proprietären KI-Plattformen
- Planbare Kosten: Feste Infrastrukturinvestition statt Pay-per-Token
- Privacy by Design: Sensible Geschäftsdaten bleiben in Ihrer kontrollierten Umgebung
Der Rechner hilft Ihnen, die notwendige Infrastruktur für echte Souveräne KI-Implementierung zu planen.
Rechtlicher Hinweis
Wichtig: Dieser Rechner ist ein unverbindliches Planungstool und stellt kein Verkaufsangebot dar.
Die Berechnungen basieren auf unserer Erfahrung, Schätzungen, Standardannahmen und Benchmark-Daten aus öffentlich verfügbaren Quellen. Kontaktieren Sie uns für präzise Berechnungen.